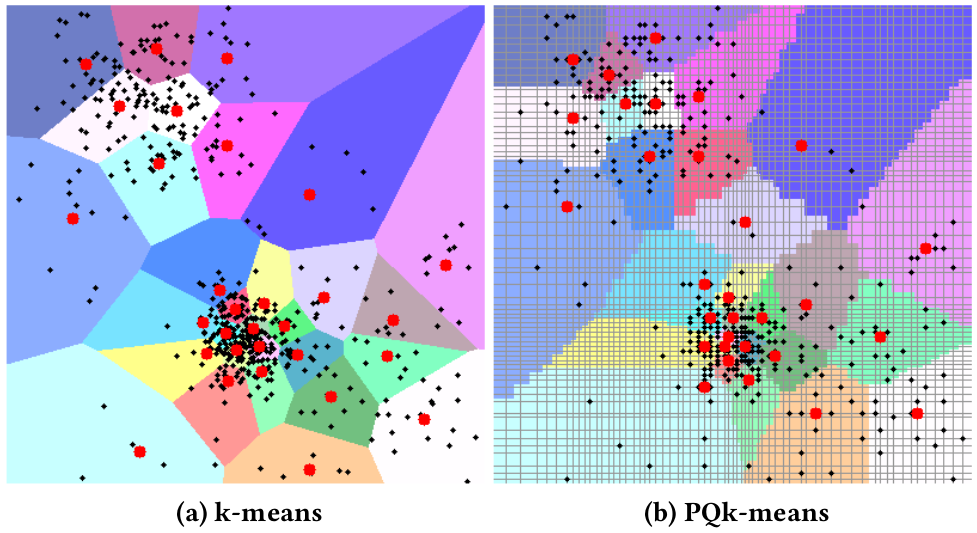
k-meansとPQk-meansの二次元の例
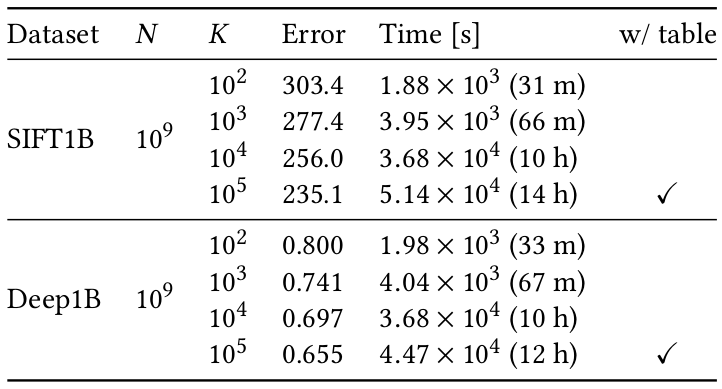
大規模評価実験の結果
Abstract
データ分析において,データのクラスタリングは最も基礎的で重要な処理の一つです. 大規模データを扱う場合,標準的なクラスタリング手法であるk-meansは実行速度が遅いだけでなく,メモリ消費量が多いという弱点がありました. そこで,我々はデータ(入力ベクトル)が10億個程度あっても高速に動作する,PQk-meansというクラスタリング手法を提案します. 事前に入力ベクトルを直積量子化コードに圧縮し,圧縮された世界で処理を行うことで, PQk-meansは高次元データに対しても高速かつ省メモリでクラスタリングを実行します. k-meansと同様に,PQk-meansは「割り付けステップ」と「更新ステップ」を繰り返します. そのどちらのステップも,圧縮された世界で処理を行います. 我々は評価実験において,データを強く圧縮(一個のベクトルを32 bitに圧縮)しても,k-meansに近い精度を達成できることを確認しました. この結果は,メモリが少ない環境において特に重要な知見です. 提案したPQk-meansを用いることで,10億個の128次元SIFTベクトルをK=10万個に分割する処理を, わずか14時間で,かつ32GB以下のメモリ使用量の通常のコンピュータ一台で実行できました.
Install
- pip install pqkmeans
Publication
-
PQk-means: Billion-scale Clustering for Product-quantized Codes
Yusuke Matsui, Keisuke Ogaki, Toshihiko Yamasaki, Kiyoharu Aizawa
ACM International Conference on Multimedia (ACMMM), 2017
BibTeX
@inproceedings{acmmm_matsui_2017,
author={Yusuke Matsui and Keisuke Ogaki and Toshihiko Yamasaki and Kiyoharu Aizawa},
title={PQk-means: Billion-scale Clustering for Product-quantized Codes},
booktitle={ACM International Conference on Multimedia (ACMMM)},
pages={1725--1733},
year={2017}
}