ACM International Conference on Multimedia (ACMMM) 2017
PQk-means: Billion-scale Clustering for Product-quantized Codes
Yusuke Matsui*
- National Institute of Informatics (*Joint first authors)
Keisuke Ogaki*
- DWANGO (*Joint first authors)
Toshihiko Yamasaki
- The University of Tokyo
Kiyoharu Aizawa
- The University of Tokyo
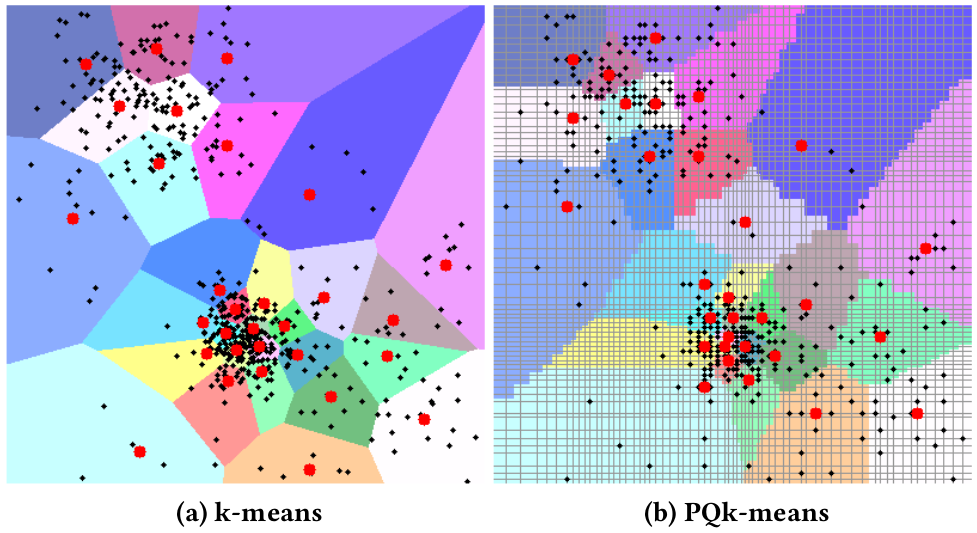
A 2D example using both k-means and PQk-means.
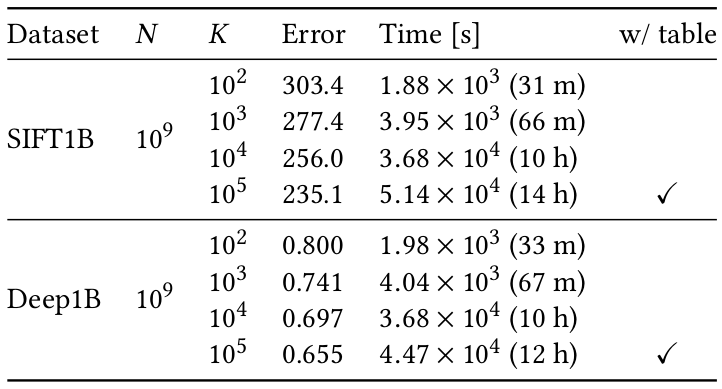
Large-scale evaluation.
Abstract
Data clustering is a fundamental operation in data analysis. For handling large-scale data, the standard k-means clustering method is not only slow, but also memory-inefficient. We propose an efficient clustering method for billion-scale feature vectors, called PQk-means. By first compressing input vectors into short product-quantized (PQ) codes, PQk-means achieves fast and memory-efficient clustering, even for high-dimensional vectors. Similar to k-means, PQk-means repeats the assignment and update steps, both of which can be performed in the PQ-code domain. Experimental results show that even short-length (32 bit) PQ-codes can produce competitive results compared with k-means. This result is of practical importance for clustering in memory-restricted environments. Using the proposed PQk-means scheme, the clustering of one billion 128D SIFT features with K = 10^5 is achieved within 14 hours, using just 32 GB of memory consumption on a single computer.
Install
- pip install pqkmeans
Publication
-
PQk-means: Billion-scale Clustering for Product-quantized Codes
Yusuke Matsui, Keisuke Ogaki, Toshihiko Yamasaki, Kiyoharu Aizawa
ACM International Conference on Multimedia (ACMMM), 2017
BibTeX
@inproceedings{acmmm_matsui_2017,
author={Yusuke Matsui and Keisuke Ogaki and Toshihiko Yamasaki and Kiyoharu Aizawa},
title={PQk-means: Billion-scale Clustering for Product-quantized Codes},
booktitle={ACM International Conference on Multimedia (ACMMM)},
pages={1725--1733},
year={2017}
}